Casi todos mis clientes prefieren hablar antes que escribir. Me llegan audios de WhatsApp de tres, cinco, ocho minutos, con cambios de tema, ruido de fondo y la duda final del tipo “che, ¿y si lo hacemos en azul?”. Escucharlos en tiempo real no escala. Tomar notas mientras se escuchan, tampoco.
Lo natural era tirarle el audio a una API de transcripción y listo. Pero no quería:
- Pagar por minuto algo que voy a usar todos los días.
- Subir audios de clientes a un servicio que no controlo — ahí adentro a veces dicen contraseñas o cosas que prefieren no repetir.
- Quedar atada a un proveedor que mañana cambia los precios.
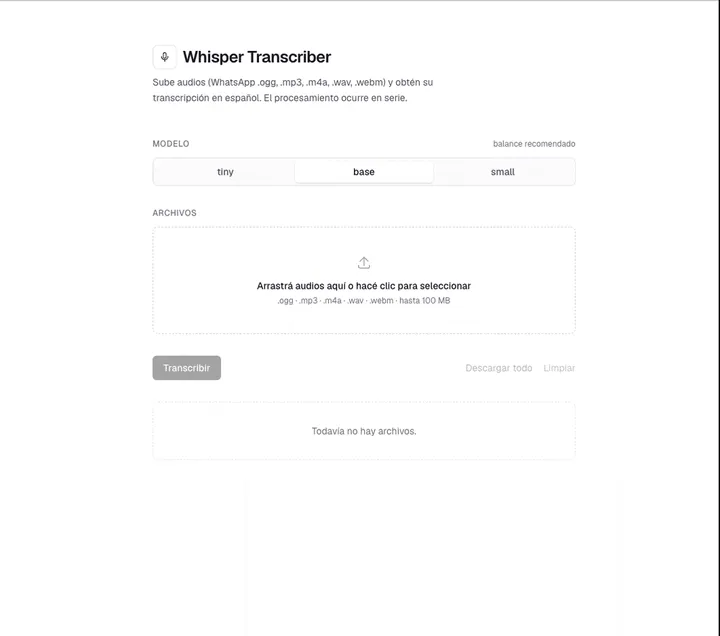
Esta mañana no sabía que existía Whisper. Esta tarde tengo whisper-transcriber corriendo: una app web local que toma archivos, los transcribe en español y devuelve .txt. Todo dentro de un contenedor, sin enviar audio a internet.
Pero el día no empezó en Claude Code. Empezó en otra conversación.
el brief
Antes de abrir el editor, me senté con Claude (la versión chat) y le conté el problema: audios largos, en español, sin pagar APIs, sin subir nada a la nube. La conversación derivó en un plan técnico que cubría casi todo lo que después iba a necesitar — el stack, los endpoints, los detalles de configuración, hasta las decisiones de UI.
Algunas líneas del brief que yo no habría sabido escribir desde cero:
“API route en
src/app/api/transcribe/route.tsconruntime = 'nodejs'ymaxDuration = 300.”
“Guardar audios temporalmente en
/tmpdel proyecto, con nombres únicos (randomUUID). Borrar el archivo de audio y el.txtgenerado después de leer la transcripción.”
“Ajustar
bodySizeLimita50mbenexperimental.serverActions— los audios de WhatsApp pueden ser pesados.”
“Procesar los audios en SERIE, no en paralelo, para no saturar CPU/RAM.”
Cada una de esas líneas resuelve un problema que yo todavía no sabía que existía. Aprender de antemano cuáles serían los baches y cómo evitarlos — esa es la parte del trabajo que normalmente se hace tropezando una vez con cada uno.
Y la línea que cerraba el brief, mi favorita:
“Si encuentras alguna ambigüedad menor, decide tú con buen criterio y avísame al final qué decidiste.”
Esa es la disposición que abre la puerta para que la sesión siguiente sea productiva: dejar que Claude Code decida los detalles chicos sin frenarse a consultar, pero pedir que reporte al final qué decidió.
de brief a app
Pasé el brief a Claude Code. En una pasada salió la app entera: subida batch de archivos, selector de modelo (tiny, base, small), procesamiento en serie con estado visible por archivo (pendiente, procesando, listo, error), descarga individual o combinada en un solo .txt con separadores. Al final, una lista breve de “estas son las decisiones chicas que tomé” — exactamente lo que el brief le había pedido.
El corazón es una route handler de Next.js que recibe el archivo, lo guarda en tmp/, llama a whisper, lee el .txt resultante y lo devuelve:
export const runtime = "nodejs";
export const maxDuration = 300;
export async function POST(request: Request): Promise<Response> {
const formData = await request.formData();
const file = formData.get("file");
const model = formData.get("model");
if (!(file instanceof File)) {
return Response.json({ error: "Missing 'file'" }, { status: 400 });
}
if (file.size > MAX_BYTES) {
return Response.json({ error: "File too large" }, { status: 413 });
}
if (!isModel(model)) {
return Response.json({ error: "Invalid 'model'" }, { status: 400 });
}
// ...
}La validación del modelo se apoya en un type guard chiquito, así el cliente no puede forzar la descarga de un modelo que no soportamos:
export const MODELS = ["tiny", "base", "small"] as const;
export type Model = (typeof MODELS)[number];
export function isModel(value: unknown): value is Model {
return (
typeof value === "string" && (MODELS as readonly string[]).includes(value)
);
}el detalle molesto: ¿dónde quedó el .txt?
Hubo un punto en la implementación donde Claude Code y yo nos quedamos mirando el código un rato: nodejs-whisper no devuelve el path del archivo de salida. El binario whisper-cli con -otxt lo escribe junto al input, pero si internamente convirtió a wav primero, queda con otro nombre. En la práctica son tres patrones posibles:
const candidateTxtPaths = [
`${wavPath}.txt`, // si convirtió a wav
path.join(tmpDir, `${uuid}.txt`), // si soltó la extensión
`${audioPath}.txt`, // si tomó el original
];
let transcription: string | null = null;
for (const candidate of candidateTxtPaths) {
try {
transcription = await fs.readFile(candidate, "utf8");
break;
} catch {
// probar el siguiente
}
}Probar tres paths es feo, pero es honesto: refleja la realidad del wrapper. La alternativa era leer el directorio entero y filtrar, lo cual oculta el problema en vez de documentarlo. Si el día de mañana nodejs-whisper cambia el patrón, este código va a fallar de manera ruidosa y clara.
el Dockerfile, una iteración aparte
El brief no decía nada de Docker. Una vez que la app andaba, le pedí a Claude Code que la empaquetara para poder correrla en cualquier máquina sin depender de mi entorno. Ahí salió el Dockerfile, que terminó siendo la parte del proyecto donde más diferencia hizo trabajar con un asistente.
Es un Dockerfile no trivial: multi-stage, compilación nativa de whisper.cpp, modelos pre-descargados desde Hugging Face en build time, capas pensadas para cachear, slim del árbol antes del runtime. Yo nunca había escrito uno así.
FROM node:22-bookworm AS builder
RUN apt-get update && apt-get install -y --no-install-recommends \
ffmpeg cmake build-essential curl ca-certificates \
&& rm -rf /var/lib/apt/lists/*
RUN corepack enable
WORKDIR /app
COPY package.json pnpm-lock.yaml ./
RUN pnpm install --frozen-lockfile --config.package-import-method=copy
ENV WHISPER_CPP_DIR=/app/node_modules/nodejs-whisper/cpp/whisper.cpp
RUN ARCH=$(uname -m) \
&& if [ "$ARCH" = "aarch64" ] || [ "$ARCH" = "arm64" ]; then \
EXTRA_CMAKE_FLAGS="-DCMAKE_C_FLAGS=-march=armv8.2-a+dotprod+fp16 -DCMAKE_CXX_FLAGS=-march=armv8.2-a+dotprod+fp16"; \
else \
EXTRA_CMAKE_FLAGS=""; \
fi \
&& cmake -B "$WHISPER_CPP_DIR/build" -S "$WHISPER_CPP_DIR" \
-DCMAKE_BUILD_TYPE=Release \
-DGGML_NATIVE=OFF \
$EXTRA_CMAKE_FLAGS \
&& cmake --build "$WHISPER_CPP_DIR/build" --config Release -j "$(nproc)"Tres detalles ahí que yo no habría sabido buscar por mi cuenta:
package-import-method=copyen pnpm — para quenode_modulesse pueda copiar limpio al stage de runtime sin hardlinks rotos al store global.GGML_NATIVE=OFF— evita que cmake pase-march=native, que es poco confiable dentro de un contenedor (la imagen se puede construir en una máquina y correr en otra).- Los flags específicos de ARM64 — en Apple Silicon, los intrínsecos NEON con dotprod requieren explícitamente
armv8.2-a+dotprod+fp16o gcc 12 falla con"target specific option mismatch".
Cualquiera de los tres por separado me habría costado una tarde de Googlear. Los tres juntos en un bloque que entiendo lo bastante como para mantener: eso es lo nuevo.
Después siguen los modelos en build time (no en runtime, para que el contenedor arranque sin internet), la copia del código de la app, el build de Next, y un slim del árbol que tira todo lo que no se necesita en producción:
RUN pnpm prune --prod \
&& cd "$WHISPER_CPP_DIR/build" \
&& find . -type f \
! -name 'whisper-cli' \
! -name '*.so' \
! -name '*.so.*' \
-delete \
&& find . -depth -type d -empty -deletePasa solo el binario whisper-cli y sus .so enlazadas al stage final. Sin esa pasada, la imagen pesaba casi el doble por archivos intermedios de cmake, tests, ejemplos y shaders de Metal que en Linux no se usan.
el flujo, de afuera
Una vez construida la imagen:
docker run --rm -p 3000:3000 whisper-transcriberAbro localhost:3000, arrastro los .ogg que descargué de WhatsApp (o cualquier otro audio), elijo base, presiono Transcribir todo. Treinta segundos por audio de tres minutos, más o menos. Descargo un .txt por archivo o todos juntos pegados.
dos Claudes, dos modos
Lo que me llevo del día no es la app — es el flujo de dos tiempos.
Claude chat para pensar. La parte donde no sabés todavía qué herramientas existen, qué stack tiene sentido, qué decisiones técnicas hay que tomar antes de tocar código. Una conversación abierta produce un brief que vos no habrías escrito desde cero. Lo notable no es que Claude sepa de whisper.cpp — eso es búsqueda. Lo notable es que, en la misma conversación, te traduce ese conocimiento a una especificación concreta para tu caso: route handler, paths, configuración, restricciones.
Claude Code para construir. El brief es la entrada. La sesión va de “código que existe + brief” a “código que cumple el brief”. Acá la conversación es más quirúrgica: errores, ajustes, decisiones de bajo nivel. La línea final del brief — “decide tú con buen criterio y avísame al final qué decidiste” — es lo que hace que la sesión fluya en vez de detenerse cada cinco minutos.
Lo que se ahorra entre los dos: la parte de aprender desde cero las cinco capas técnicas que el proyecto pisa. La parte que me sigue tocando — entender, decidir, corregir — es la misma que cuando programo sin asistencia.
Lo que me deja pensando es cuántos problemas chicos del día a día, de los que normalmente uno se resigna a “pago la API y listo”, caben ahora dentro de “una conversación para pensarlo + un par de horas para construirlo”.
El código está en GitHub. Un docker build, un docker run, y lo tenés andando.